This White Paper explores the concept of the ‘Best Source of Compute.’ It is an overview of the considerations that application owners and stakeholders should apply when determining where to manage workload execution. Proliferation of choice means that the on-premise and cloud landscape for identifying suitable compute and placing workloads is highly complex and is trending towards becoming even more so with new machine types, configurations and new locations becoming increasingly available. A data driven, automatic decision-making framework to determine what and where is the best source of compute is essential to ensure workloads execute securely, comply with regulation and complete on time using the most optimal combinations of cost, performance and other attributes. This allows enterprises and businesses to better achieve the scale and opportunity offered by cloud while maintaining high utilisation of existing hardware.

We are all familiar with comparison sites that help consumers find the best insurance, best credit card, best car, best time to take a trip. Consumers enter requirements, select product features they value, and a list of ranked options is returned. Consumers choose what they want. But why? The primary consideration is to get the best deal, that’s right for the consumer’s needs, and technology makes it relatively easy to do.
But can this type of consumer technology be appropriated for workload management and placement? Can we get the best deal for workloads to execute?
Let’s put some perspective on the cloud landscape first.


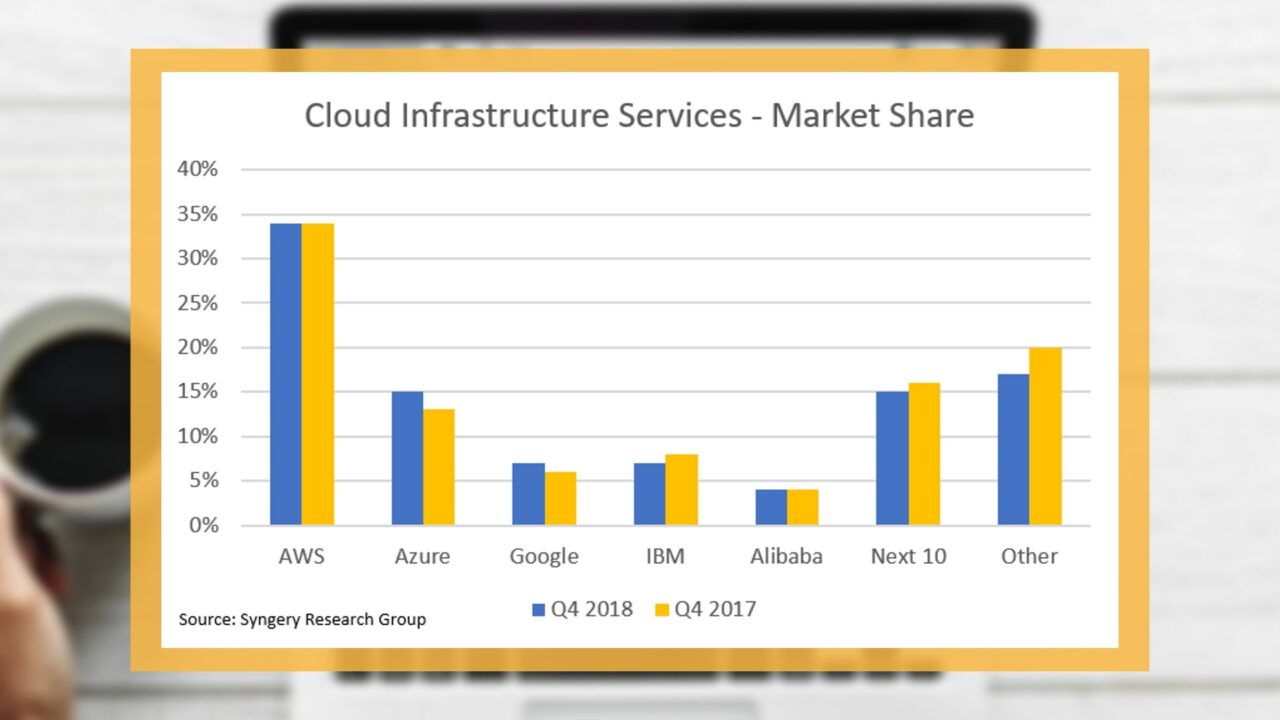
We can see by the numbers that cloud is a complex landscape. To add more complexity in to the mix, businesses are adopting hybrid and multi-cloud deployments where companies mix resources from on-premise and multiple cloud providers. To the last point, research by IDC found that, in 2018, more than 85% of enterprise IT organisations had committed to multi-cloud architecture.
What is the best deal for workloads to execute? The “deal” for workloads is the compute source that will ensure that they are completed according to the business’ requirements. The Best Source of Compute is a methodology for determining the best place to execute a workload, considering deadline, cost, performance, security, regulation, location and other characteristics which are important to a business.
Businesses want their workloads to complete on time. They want to predictably repeat these completions, especially during key crunch and reporting periods. However, businesses should not do this to the detriment of cost, efficiency, and compliance with policy. Businesses need to apply control to prevent waste, workload sprawl and to avoid regulatory or security breaches. Otherwise the true scale and opportunity provided by cloud (reduced IT costs, faster speed to market, and better service levels) cannot be achieved and its use becomes less palatable.
Gartner reports that average data centre server utilisation is only between 5 and 15%, and 30% of all machines installed and turned on in data centres are never used.
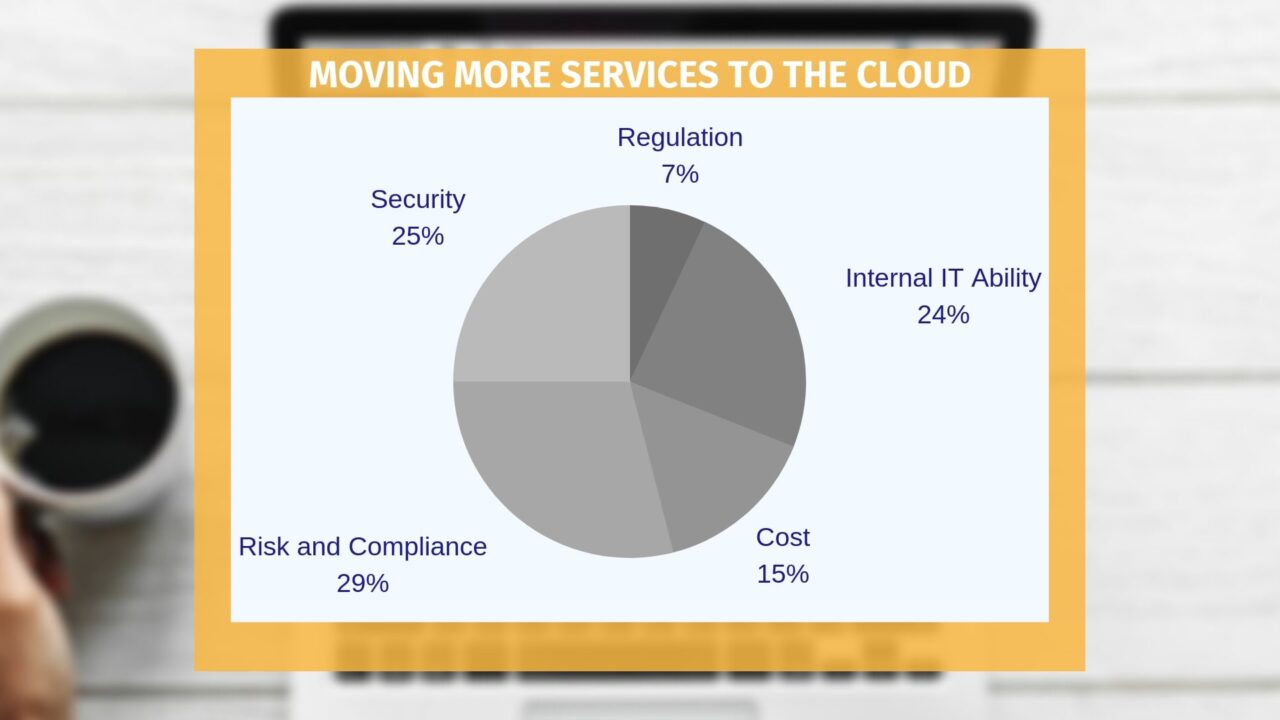
In a 2019 survey by YellowDog, 29% of technology leaders say Risk and Compliance is a principal factor stopping them moving more services to cloud; 25% quote Security as another barrier.
A 2019 survey by Accenture echoes the YellowDog survey, stating that 65% of respondents cited Security and Compliance Risk being a barrier to realising the benefits of cloud. Only about one-third reported they have fully achieved their expected outcomes across the categories of cost (34%), speed (36%), business enablement (35%), and service levels (34%).
Deciding ‘best’ is similar to what we see on consumer comparison sites, a set of required workload criteria are matched to suitable resources providing these criteria and then ranked with resources providing the best match listed as top.
What are the criteria that should be used to decide what and where is the best source of compute for a workload? Below are some examples businesses should consider.
Taken in isolation, matching a workload with a single criterion to compute resource is not complicated. For example, a compute resource may be selected purely on cost, i.e. “give me the lowest cost resource for my workload”. However, in reality, finding the best source of compute involves combining a number of attributes; some weighted higher than others to produce a “blended” criteria list, which can be compared against compute source attributes. The “radar” graph diagrams below highlight different choice combinations with particular sensitivities to; Performance and Availability, Cost and lastly Regulatory and Security.
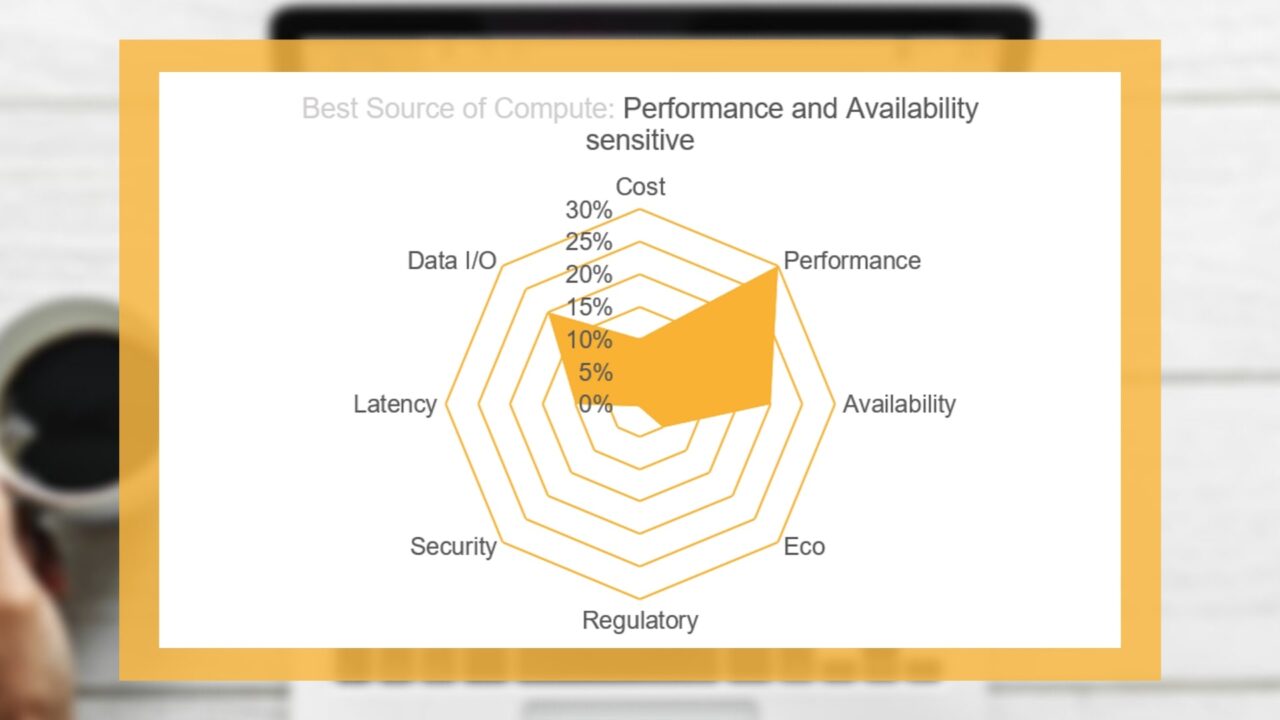
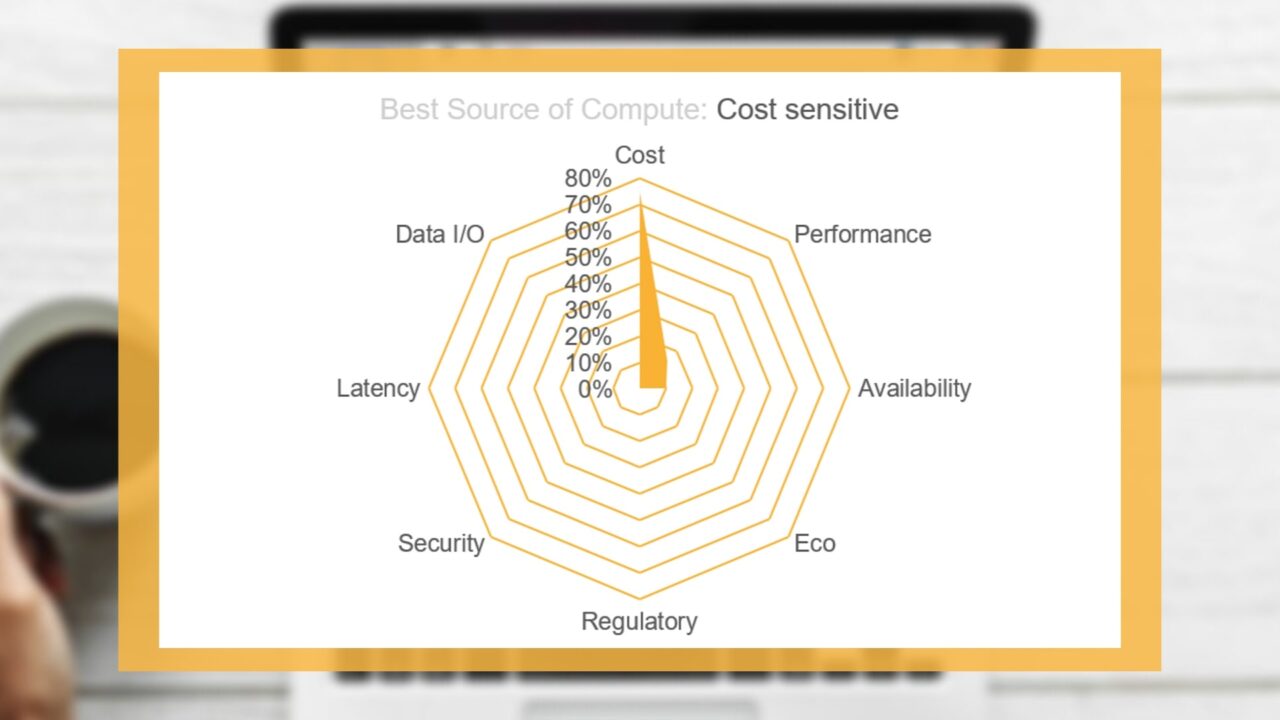
Once chosen, the business’ provisioning infrastructure locates and provides the best source, delivers the workload and the workload is executed. But, if best source is unavailable and cannot be obtained, what next? The provisioning infrastructure should then locate and look to use the next best, the next best and so on. So, what we are seeing is a ranked best source list that should be utilised top down until the best available is provisioned and used for workload execution.

Lastly, there may be occasions where a “panic button” must be used. Workloads may be moved to sources which may be able to execute the workload quickly but have to bypass the other factors that would normally constrain what may be used. This scenario of course is one which all businesses would want to avoid but should be an important feature in this methodology as there will be crunch times.
So far, we have seen that cloud scale is huge and complex and the choices that businesses need to make are numerous. Given businesses have huge amounts of workloads that need to be processed, and that the cloud and on-premise landscape and characteristics can change minute to minute, how does a business determine best source of compute for every workload? In short, all decisions should be automated with data used to drive those changes. One might argue that heuristics, nous or intuition could be applied to decision making, but studies have shown over time that machine decision making outperforms humans. The Harvard Business Review for example, have cited, “Statistical decision rules work best when objectives are clearly defined and when data is available on past outcomes and their leading indicators. When these criteria are satisfied, statistically informed decisions often outperform the experience and intuition of experts”.
Decisions made, whether they are made by machine or human will only be as good as the data that supports them. Untimely or incorrect data will produce sub-optimal and possibly costly results. In addition, workload requirements and the attributes of on-premise and cloud resources will change over time. Therefore, it is crucial that any methodology which determines best source should be extensible and, most importantly, be updated frequently with new data and new insights calculated. Compute sources need to be actively and rigorously benchmarked to ensure that actual data (e.g. machine performance, latency, data I/O rates etc.) is up to date and is characterised across many different locations, time frames and operational scenarios. For example, due to the multi-tenancy and resource sharing nature of cloud, the phenomenon of noisy neighbours is well documented. Noisy neighbours cause server performance degradation in shared infrastructure due to their high utilisation using most system resources.

When looking at compute attributes that are variable in nature, predicting likely future values is advantageous. Otherwise best source of compute decisions may result in attempting to get compute that is unavailable or unsuitable at that moment in time and consuming cycles in trying to obtain the resource. Compute attribute requirements that are variable in nature include availability, latency and certain aspects of performance. Cloud availability in particular has been very much at the fore recently, due to notable outages at Google Compute Platform (June 2019) and Azure (May 2019). The usage of “Spot” or “Preemptable” resources to save costs can also have an adverse effect on availability.
Machine learning algorithms should be applied to this data to identify trends when compute source attributes diverge. In particular, machine learning can be highly effective with best placement around resource availability, performance and latency rates when workloads are sent for execution.

Though not usually at the forefront, audit and reporting on the determination of best source of compute is crucial. It allows all stakeholders to understand the value of the methodologies, data and insights that using a best source of compute methodology brings.
Reporting should compare the cost and performance of workloads against previous executions of the same workload; highlighting where optimisations could be made to cost, performance and availability choices. Insights into workload scheduling are also vital to know, as further improvements can also be made by intelligently scheduling workloads using predictive algorithms to optimise workload execution times given the availability of the best source of compute.

Why should businesses choose Best Source of Compute?
Choosing the Best Source of Compute is vital to ensure that workloads execute on-time, securely, and in a compliant manner whilst optimising cost and performance. Otherwise the risks of higher costs, waste, regulatory and operational issues can increase due to not applying control to a landscape that is vast and complex.
What are the steps to Best Source of Compute?
The methodology chosen to determine and manage best source of compute should have the following characteristics:
Gets you the best source of compute for your workload every time.
YellowDog enables companies across the globe to accelerate and optimise complex data processes with the only intelligent and predictive scheduling and orchestration platform for hybrid and multi-cloud management. We serve organisations in Financial Services, Aerospace, and CGI amongst others. The technology automates the selection of the best source of compute for every workload, delivering new levels of prediction and efficiency in cost and performance optimisation.
Interested in Learning More?
If you require more information on any of the topics in this document, or you want to find out how YellowDog could help you in your multi-cloud journey, email sales@yellowdog.co with your contact details and one of the team will get in touch.
To book a demo of the YellowDog Platform, or to ask our team for further information, you're just a click away!
You are seeing this because you are using a browser that is not supported. The YellowDog website is built using modern technology and standards. We recommend upgrading your browser with one of the following to properly view our website:
Windows MacPlease note that this is not an exhaustive list of browsers. We also do not intend to recommend a particular manufacturer's browser over another's; only to suggest upgrading to a browser version that is compliant with current standards to give you the best and most secure browsing experience.