The rise of cloud and IT has been meteoric. The factors that have driven growth along with narratives on typical enterprise cloud strategy are explored and analysed at market level.
Through this analysis, it is possible to succinctly describe the challenges and opportunities of cloud. Opportunities range from high levels of innovation to cost savings; whilst challenges can include security and regulatory exposure, if executed badly.
Happily, multi-cloud adoption is a growing, and some would argue necessary, trend in cloud strategy, for its ability to capitalise upon opportunities and mitigate some of the challenges of cloud.
These abilities underpin the steps for achieving optimal multi-cloud implementation. Guidance is structured as five key steps which are: prepare, deploy, control, scale, optimise.
Each step is described and shared in this white paper based on YellowDog’s first-hand experience of implementing multi-cloud solutions for some of its clients.

The rise of the cloud in modern business use has been meteoric. Since the launch of AWS in March 2006, there has been a fundamental shift in how and where businesses run and operate their IT infrastructure. Traditionally, IT was run on their own premises (on-premise), within data centres, and under the total control of the IT department. Security, scalability, availability, compatibility, performance were all important considerations and systems and processes were designed and invested in accordingly.
Rapid cloud adoption has meant that a lot of IT is run on third party shared infrastructure: with infrastructure that is no longer in direct control of the IT department (and the characteristics of how the environment operates) purchased as products to improve or tailor performance. Security, scalability, availability, compatibility, performance continue to be primary considerations for any design and implementation.
The International Data Corporation (IDC), a global provider of market intelligence and advisory services, noted in their paper ‘The Salesforce Economy’ that cloud spend will grow at six times the rate of general IT expenditure through to 2020. However, that delegation of accountability to third party vendors has brought with it both opportunities and challenges.

Given the speed and scale of cloud adoption, the opportunities and benefits are clearly real. But there are some significant challenges that need to be addressed:

AWS has been the dominant supplier in the cloud market, with Google’s Compute Platform (GCP) and Microsoft Azure catching up fast, especially in the enterprise market. Oracle’s Cloud Infrastructure, Alibaba Cloud, OVH, Rackspace, IBM Softlayer all vie for market share. As markets tend to with strong competition, base services and prices are becoming commoditised, and cloud vendors look to differentiate their offers with new ‘value-add’ services on top of base compute and storage offers.
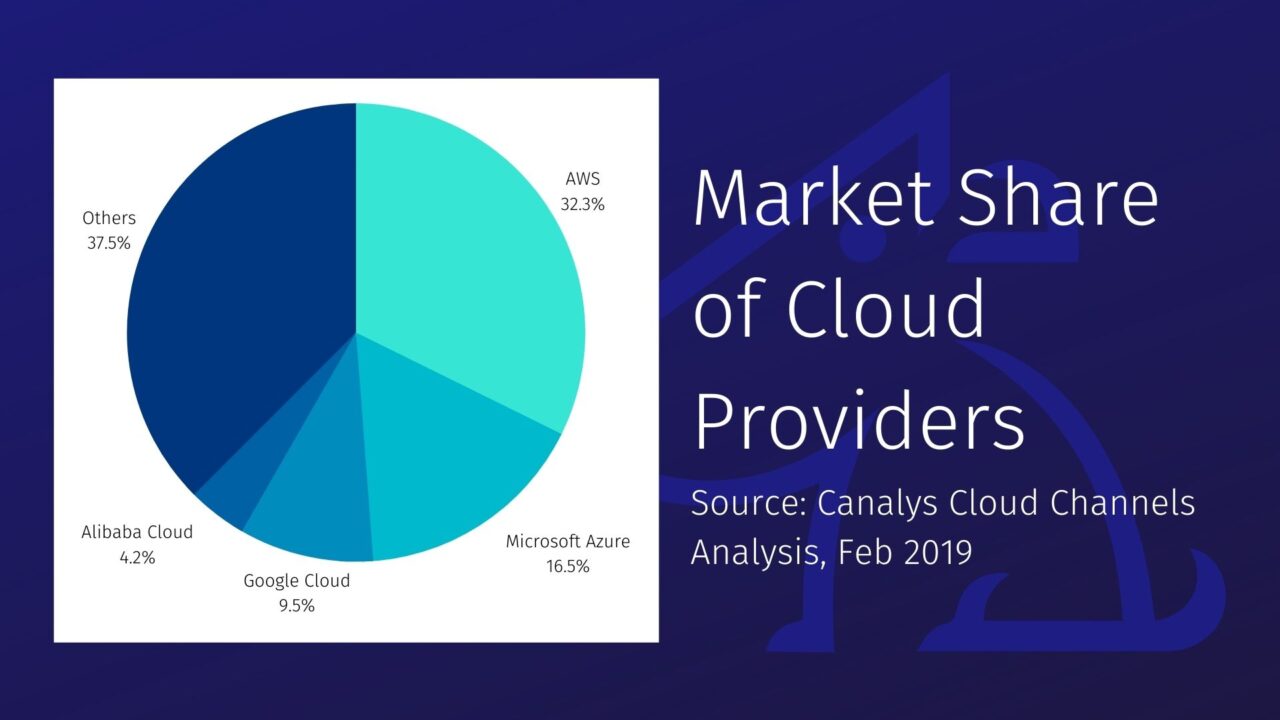
However, there are sometimes subtle, sometimes obvious, differences between those base offers meaning that deploying applications and services across multiple clouds is less straightforward than it would appear at first sight.
The desire to deploy applications across multiple clouds is something that is becoming an increasing need for many businesses. This is being driven by multiple factors:
Clearly, the challenges of deploying to the Cloud are exacerbated when a multi-cloud deployment is being considered: design, implementation, deployment, compliance, operations, cost, performance, availability all become more complex when the underlying value chain and environment is more complex. However, it is becoming evident that the benefits of a multi-cloud deployment, and one that treats on-premise resource as part of that multi-cloud deployment, are outweighing these challenges as more and more businesses adopt multi-cloud strategies.

There are five recommended steps to embarking on and successfully completing the multi-cloud journey:
The first part of preparation is the mindset and cultural shift required for the development, operations and management teams that will be using multi-cloud. For example, physical ‘hosts’ and ‘servers’ no longer exist; it’s more about services and dynamic pools of infrastructure that will exist for varying periods of time. Services are discovered and configured at runtime rather than pre-configured and deployed. Secrets are dynamic with multiple users and identity sources, rather than using IP or hardcoded secrets for access and authentication. Instances are separated from their applications, dedicated hosts are typically not used. Budgets are opex, rather than capex.
Once the mindset shift has begun, then the right cloud needs to be selected for the right workloads. Different cloud providers’ infrastructures have different characteristics and services available, as well as varying prices – the right selection needs to be chosen for the business and application needs.

It may be the case that the applications and processes destined for the multi-cloud need adapting and configuring so that their performance is optimal in the cloud. If the legacy application cannot work effectively there, then a new application may have to be written or purchased.
Using fully configurable infrastructure code and other cloud native tools is the right way to go about deploying applications and processes across multiple clouds. Cloud providers expose their services using APIs, and infrastructure as code helps with reusability, ensuring optimum efficiency at scale.
Part of that automation needs to take into consideration any and all regulation and policies on where particular types of data can be processed. Legislation such as Europe’s GDPR mean that in highly complex, international, multi-cloud deployments, additional intelligence, ideally through deep learning and AI, needs to be employed to ensure control, governance and transparency, as well as to avoid significant fines and loss of customer trust.

Secure data transfer from originating destinations to processing centres which may be on the other side of the world, need to be achieved. Establishing fully meshed private networks may not be practical or economical, so it may be necessary to treat every data transfer link as untrusted. Therefore, security teams must look at how to encrypt application data both in-flight and at-rest, but in a way that does not affect application performance.
The criticality and exponential scale of multi-cloud deployments means that automation is imperative to ensure that service level agreements are adhered to, and that operational costs are kept under control as the number of deployments increase. Integration to the various vendors APIs to achieve that automation is therefore needed, and a common control plane and interface required to ensure that there is the right level of scheduling and orchestration across the multi-cloud deployment to provision and decommission servers as they are required.
Understanding the best source of compute for each workload and process at that point in time across the multiple clouds is important to ensure that performance, cost, compliance and regulatory requirements are met. Given the number of options that present themselves during any enterprise multi-cloud deployment, the ability to automatically choose the best source of compute, based on business rules or deep learning, becomes important.

Having the ability to configure the multi-cloud deployment both through a command line interface and through an intuitive user interface (GUI) provides the right mix of control interfaces for different types of development, operations, administrative and DevOps roles across the business. Visualisation dashboards and integrations into off the shelf operations, alerting and management platforms then enables the ongoing monitoring and control in an easy-to-digest and transparent manner.
Scaling can be achieved by adding more sources of computing power to the infrastructure: more data centres owned by the business, more regions from a cloud vendor or multiple cloud vendors.
Before additional hardware is bought or more regions or vendors are added to the mix, it’s worth considering whether the existing IT estate within a business can be more effectively utilised. The Uptime Institute and other analysts have shown that the average server utilisation within an enterprise is only between 5% & 15% and that 30% of servers that are deployed into data centres are turned on and then never used; they are effectively comatose. Deploying agents onto these servers so that they too can be added to the pools of cloud resources may be a cost effective, and inherently compliant, first step in scaling the amount of compute available.
Certain processes can be accelerated by distributing them over many thousands of computing cores. Segmenting and distributing those jobs over multiple cloud providers can often be achieved by using existing grid and scheduling engines although care and consideration needs to be taken to ensure that the underlying application data is also segmented and securely transferred to the processing centres correctly and compliantly.

Log-based performance monitoring and alerting, brought together and aggregated using some of the newer cloud native technologies, provides the ability to scale much further and wider than the traditional metrics-based monitoring that was used in IT environments a decade ago. Ensuring full monitoring, visibility and observability across the entire multi-cloud deployment and through the application stack is then vital for making sure that any scaling is happening in a performant and effect manner.
Optimising both costs and performance is necessary in any IT infrastructure, indeed in any business, and is doubly-so in a multi-cloud environment. It is made more complex when the performance characteristics of clouds varies between vendors, between generations of hardware and when load on infrastructure varies. When time-critical processing jobs are run in a multi-cloud environment, it becomes important to measure the aggregate computing power that is being provided to those processes to ensure that the computing budget is sufficient to deliver those processes on time. There may be regulatory or customer fines if those processes are delivered late, for instance. Once computing power is being accurately and effectively measured, steps can then be taken to ensure that the right amount of computing power is always available to deliver those processes on time, and on budget, by automatically normalising the addition and removal of computers as the aggregate power decreases and increases.
In an external cloud environment, the process is sent to a pool of computing power where charges are incurred by the hour, minute or second. It’s therefore vital that the usage of compute and storage is as efficient as possible. It may be possible that the existing grid engine or scheduler within a business is able to do this, if not, it may be necessary to source and deploy a cloud native scheduler that does this job more effectively.

Having accurate insight as to when a process is likely to finish, or its likelihood of failure, helps to further optimise the operational environment. When the system knows with a high degree of confidence how long a process will take, the level of sophistication and efficiency of the scheduling of that job increases by multiple factors. This not only helps with increased capex and opex efficiency, but it also means that compliance with regulatory and customer service level agreements is always achieved. Insight like this can only be delivered with advanced machine learning.
Whilst there are many challenges, the advantages that many businesses are now realising through using the cloud can be expanded by embracing multi-cloud deployments which, at the same time, help to mitigate risks associated with only ever using one vendor. To ensure the full success of multi-cloud deployments, it’s recommended to approach the project in five distinct stages: prepare, deploy, control, scale, optimise; and it’s likely that sophisticated and cloud native technologies, like YellowDog’s intelligent predictive orchestration and scheduling platform, can both mitigate operational risks as well as maximise the commercial opportunities.
YellowDog enables companies across the globe to accelerate and optimise complex data processes with the only intelligent and predictive scheduling and orchestration platform for hybrid and multi-cloud workload management. Our Platform can help multiple solutions, including weather prediction, drug discovery and rendering CGI – amongst others. The technology automates the selection of the Best Source of Compute for every workload, delivering greater levels of efficiency in cost and performance optimisation.
Interested in learning more?
If you would like more information on any of the topics covered in this white paper, or you want to find out how YellowDog could help you in your multi-cloud journey, email sales@yellowdog.co with your contact details, or fill out the form below, and one of the team will get in touch.
To book a demo of the YellowDog Platform, or to ask our team for further information, you're just a click away!
You are seeing this because you are using a browser that is not supported. The YellowDog website is built using modern technology and standards. We recommend upgrading your browser with one of the following to properly view our website:
Windows MacPlease note that this is not an exhaustive list of browsers. We also do not intend to recommend a particular manufacturer's browser over another's; only to suggest upgrading to a browser version that is compliant with current standards to give you the best and most secure browsing experience.